Contents
These are some projects I’m not actively working on at this time
Alphabetic Letter Similarity

This project investigates the visual representation of letter stimuli, and collects a number of data sets which have reported the visual similarity of the English alphabet, using a number of different methods. These are available in the Letter Similarity Data Set Archive.
The Cognitive Decathlon: A modern embodied Turing Test
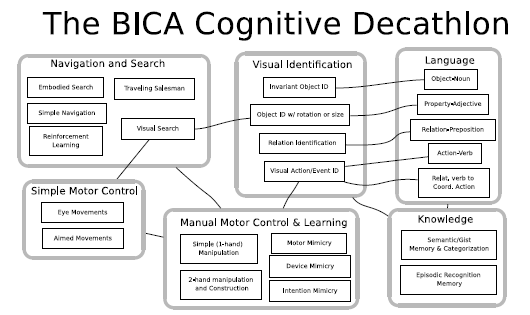
For DARPA’s BICA (Biologically-Inspired Cognitive Architecture) program, I developed what we called the “Cognitive Decathlon”, a set of select behavioral measures that would have been used to assess the capability and validity of the artificially-intelligent agents being developed for that program. I have argued1
Non-word generator software
This code, written in C, creates nonsense words based on orthographic transitions in a language corpus, based on Shannon’s method. link
The GAC 80K Corpus
By around 2005, the Mindpixel project had collected thousands of statements and measured human assessments of their correctness, as part of the GAC project. They had the goal of identifying millions of statements, but the project ended when its leader Chris McKinstry died. I had nothing to do with the project, but I did obtain the GAC 80K corpus–what was supposedly an early release of about 80,000 statements. I used this in some models of human conceptual representations. The corpus is no longer easily accessible, so I have posted it here.
Tree Distance Measures
In R, a common method for clustering is using the ‘sisters’ hierarchical clustering methods (agnes, diana, clara, and pam). These form trees to describe the similarity structure, and are part of the cluster package.
Boorman & Olivier 4 Boorman, S. A., and Olivier, D. C. (1973) Metrics on Finite Trees. Journal of Mathematical Psychology, 10, 26-59. developed metrics on hierarchical clustering trees to allow measurement of the distance between two hierarchical trees. I have implemented code for these distances, and the R software is available here. The C-distance metrics replicate those found in the above paper; the D-metrics do not–this may be an error in the program or in the original paper.